
‘Hey, is anyone using the staging site?’ is a question most software developers will be used to hearing.
You have three environments: local, staging and production. Any developer can spin up the application locally to build new features, and deploying those features to a single production destination is simple because it just needs to reflect the main branch of your Git repo. But when there are several developers who all need to share WIP features with the QA team and only one staging server on which to deploy them, what do you do?
You could time-share that server and shout across the room before each deployment; we’ve all been there. But is there a better option?
One is good, many are better
As our development team grew and our velocity increased, we found that we were encountering bottlenecks around our staging server. We had to time deployments around the availability of those doing QA (which, as a startup, was sometimes the company’s founders, who are very busy).
As you can imagine, this caused problems. Quite often, by the time the QA process began it had been so long since the feature was deployed that someone else had used the server to deploy an entirely different feature for testing. It was manageable, but confusing and frustrating.
So we sought something better.
The answer was simple. It was the same solution we had all wanted at previous jobs: fully functional, on-demand, short-lived feature deployments, with their own domain names and SSL certificates, able to be spun up and torn down with a single click.
How did we do it?
The UI and API layers of WONDR are decoupled from one another. This means that the only hard dependency of the UI is the hostname of the API to which it connects, and the only hard dependencies of the API are the hostnames and credentials of the data stores to which it connects.
We already had Kubernetes services that take care of creating SSL/TLS certificates for new deployments and updating DNS records to make them accessible to the outside world, so deploying different versions of our UI became as simple as running an optional stage in the CI/CD pipeline that used a different Kubernetes spec file and swapped out environment variables where necessary.
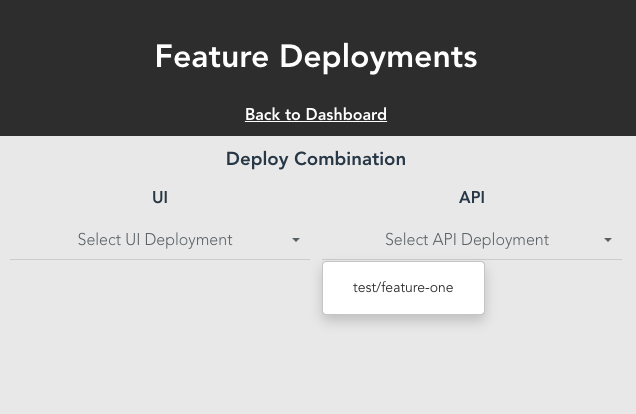
We also built a simple management tool for those doing QA to access the feature deployments and destroy them when they have finished testing.

When it comes to our API, we aim to maintain backwards compatibility wherever possible. This makes it easy to deploy several versions side-by-side that share a database, and match them with any version of our UI.
So we built the ability to run an API and UI deployment in tandem into our management tool. When executed, this makes each pipeline aware of the hostname the other will be deploying to, so that it can be set as the appropriate environment variable.
Next steps
Having solved the nagging problem of multiple developers needing to share a single staging environment, we turned our sights to a related problem: how to promote experimental feature branches to a subset of our production users in a controlled and incremental manner.
That, however, is a story for another day!